Известные проблемы
Внимание
Вносить изменения во внутренние файлы установщика можно только при взаимодействии с поддержкой VK WorkSpace. Не изменяйте файлы установщика самостоятельно.
Как восстановить репликацию БД Tarantool
Overlord требует работы с выключенной синхронной репликацией. Убедитесь, что синхронная репликация отключена с помощью команд:
box.info.synchro.queue.owner— владелец синхронной очереди. Правильное значение:0.box.cfg.election_mode— тип выборов встроенных в tarantool. Правильное значение:off.
Если не будет выключена синхронная репликация, то будет конфликт с overlord.
Пример проблемы:
фев 20 11:56:18 dev15 onpremise-container-autogen-tar1[2540431]: 2026-02-20
11:56:18.829 [42] main/103/autogen.lua box.cc:358 E> ER_READONLY: Can't modify
data on a read-only instance - synchro queue with term 2 belongs to 1 (ca425674
8af3-488e-a21f-dfad79a887a6) and is frozen until promotion
фев 20 11:56:18 dev15 onpremise-container-autogen-tar1[2540431]: 2026-02-20
11:56:18.829 [42] main box.cc:358 E> ER_READONLY: Can't modify data on a read-only
instance - synchro queue with term 2 belongs to 1 (ca425674-8af3-488e-a21f
dfad79a887a6) and is frozen until promotion
Решение
-
Найдите работающий контейнер Tarantool в системе:
В качестве примера предположим, что это контейнер autogen-tar2.
-
Перейдите в консоль Tarantool:
-
Проверьте, что режим выборов выключен через команду
box.cfg.election_mode. Правильное значение:off.Если указано другое значение, выполните команду
box.cfg{election_mode="off"}. -
Определите владельца очереди, с помощью команды
box.info.synchro.queue.owner: -
Убедитесь, что текущий контейнер является владельцем синхронной очереди:
box.info.id. Если id совпадает со значением из предыдущего шага, то выполните команду:Если id не совпадает выполните две команды:
-
Убедитесь, что владелец синхронной очереди имеет идентификатор
0. - Выполните up_container для неработающих Tarantool'ов.
Ошибки в контейнере consul при формировании кластера
Симптом:
В логах контейнера consul есть следующие ошибки:
failed to parse /etc/consul.d/server_metadata.json: 1 error occurred: * invalid config key last_seen_unix
Решение:
-
При формировании кластера consul, после перезагрузки ВМ, выполните команду по примеру:
-
Повторите команду для каждого контейнера consul в кластере.
- Выполните шаг up_container для каждого контейнера consul в веб-интерфейсе установщика.
- В веб-интерфейсе установщика проверьте состояние кластера БД MySQL на странице Настройки -> Шардирование и репликация БД, по кнопке Опросить базы данных.
Наблюдаются задержки и замедления в работе etcd
Проблема преобладает на установках с сильно перегруженной сетью.
Симптом:
В логах mailetcd можно наблюдать такие предупреждения:
{"level":"warn","ts":"2025-12-19T07:24:30.529512+0300","caller":"etcdserver/util.go:170","msg":"apply request took too long","took":"5.000138281s","expected-duration":"100ms","prefix":"read-only range ","request":"key:\"/mailonpremise/overlord/clusters/snooze-queue-tar-1/\" range_end:\"/mailonpremise/overlord/clusters/snooze-queue-tar-10\" ","response":"","error":"context deadline exceeded"}
Рекомендации по устранению:
Основной способ устранения проблемы: снизить количество обращений к ETCD.
Для этого увеличьте таймаут на запросы:
- В веб-интерфейсе установщика перейдите на страницу Настройки -> Переменные окружения.
- Для всех ролей с тегом Tarantool нужно изменить переменную
OVERLORD_ELECTION_TIMEOUT. - В поле Значение переменной укажите
(5s, 15s]. - Нажмите кнопку Сохранить.
- Выполните шаг up_container для всех машин с тегом Tarantool.
После этого важно наблюдать за состоянием системы:
- В логах mailetcd снилизилось количество предупреждений о слишком долгих запросах.
- Контейнеры не перезапускаются слишком часто. Можно посмотреть с помощью команды
docker ps -a. - В дашборде Grafana Database -> Etcd, графики: RPC Rate, High Number Of Failed HTTP Requests, Client Traffic In.
- В дашборде Grafana Database -> Overlording, графики: Overlord Restarts, Failed ETCD Requests.
Если ситуация не улучшилась, то увеличьте интервал для OVERLORD_ELECTION_TIMEOUT.
Как восстановить бакеты(bucket) в Zepto
Внимание
Перед восстановлением бакета сделайте бэкап всех реплик, которые его обрабатывают.
Бакет вышел из строя в одной из реплик
-
Найдите бакеты вышедшие из строя:
-
Найдите бакеты с неповторяющимся bid. Если bid не повторяется, значит бакет вышел из строя в одной из реплик.
-
Для каждого найденного bid запустите команду:
Внимание
Не используйте команду
zeptoctl tasks schedule --fix status!=ok. -
Проверьте статус задач:
-
Дождитесь пока закончатся все задачи. Для всех задач (task) со статусом
status = running, значение в столбцеsucceededдолжно стать равным цифре изsubtasks. -
Если задачи завершится со статусом failed, то скопируйте id задачи (task) и посмотрите причины ошибки:
Бакет вышел из строя в двух репликах
-
Определите какие bucketmaster работают с проблемном бакетом:
-
Найдите файлы в директориях bucketmaster, например:
-
Сделайте копию-бекап бакета в директории всех bucketmaster, которые за ним закреплены.
-
Скопируйте полученный файл в докер контейнер на все сервисах вида
stz-*-bm. -
Чтобы определить где находится более актуальный бакет и какая ошибка возникает, выполните внутри контейнера обеих реплик команду:
-
На реплике, где более актуальный бакет, выполните:
/usr/local/zepto/bin/bucketfixer --trim-broken --out <Введите имя бакета, который будет создан с фиксом> </путь/до/бакета/внутри/контейнера/id.bucket>Если актуальность бакетов одинаковая, то команду можно выполнить в любом из бакетов.
-
Замените старый бакет на актуальный из шага 5. Путь до устаревшего бакета был получен на шаге 2.
-
Выполните команду:
Следить за статусом задачи можно с помощью:
-
Если в итоге восстановился только один бакет — в одной реплике отображается статус
succeeded, а в другойfailed, то после завершения задачи выполните:Так восстановится второй бакет.
-
Если для обоих бакетов отображается статус
failed, а в результате выполнения задачи выводится ошибка:Calling ... returned error (500): unable to read record: unexpected EOF record while scanning the data, file broken, file broken.То обратитесь к шагам по исправлению ошибки file broken
Ошибка file broken
- Измените имена бакетов, задав другое имя на каждой реплике.
- Перезапустите реплики с помощью systemctl.
-
Внутри контейнера одной из реплик выполните команду и дождитесь успешного завершения:
-
Верните названия бакетов, которые изменялись на шаге 1.
-
Выполните команду:
-
После завершения команды, выполните:
Ошибка too many replicas for bucket или bucket has location across multiple tuple
-
Выполните команду:
После этого группа должна остаться одна группа.
-
Перезапустите реплику, которая работает с этим бакетом.
-
Выполните команду:
Пользователи массово видят ошибку 500 и память calendarapi переполнена
Симптомы:
- При высокой нагрузке на систему пользователи стали массово видеть ошибку с кодом 500.
- В PostgreSQL calendarpg закончилось место.
- Высокое потребление CPU у calendarapi.
Решение:
- На машине с установщиком откройте для редактирования файл
custom_roles.yaml. -
Увеличьте значение параметра
shm_size: -
Перезапустите установщик:
-
Перейдите в веб-интерфейс установщика, в раздел Настройки -> Переменные окружения.
- В левом меню найдите calendarpg.
- Увеличьте значение переменной
SHARED_BUFFERS. Новое значение не должно превышать значение указанное в параметреshm_size. - Нажмите кнопку Сохранить.
- Выполните шаг up_container для всех машин calendarpg.
Как убрать уведомления о старых событиях при миграции календарей с MS Exchange
Проблемы:
- Если пользователь мигрируется из Exchange, то изменения в календаре синхронизируются обратно в Exchange. Это генерирует уведомления на старые события от EWS.
- Если при миграции пользователя не отключен сервис уведомлений в Почте VK WorkSpace, то по всем мигрированным событиям будут разосланы уведомления от календаря. События рассылаются даже по старым событиям.
Решение:
Внимание
Шаги ниже рекомендуется выполнять в технологическое окно, так как во время миграции не буду рассылаться уведомления по email.
-
Отключите уведомления в сервисе calendar-notifyd. Выполните команду:
В блоке ниже, в поле
emails:укажите значениеfalse: -
Выполните шаг up_container для всех контейнеров calendar-notifyd.
-
Исправьте файл конфигурации
/app/distr/VK/custom_configs/cexsy/etc/config.yaml. Уберите комемнтарии со следующих строк или добавьте их, если они отсутствуют: -
Выполните шаг up_container для всех контейнеров calendar-cexsy.
-
Выполните миграцию календарей по инструкции: Шаг 4. Выполните синхронизацию календарей
-
Включите уведомления в сервисе calendar-notifyd. Выполните команду:
В блоке ниже, в поле
emails:укажите значениеtrue: -
Выполните шаг up_container для всех контейнеров calendar-notifyd.
Не работает SSO после обновления до версии 1.24.3
Чтобы исправить проблему:
-
Проверьте наличие закрывающего символа
;в конфигурационном файле$DEPLOYER_HOME/configs/swa/nginx/auth.mail.ru.conf, где$DEPLOYER_HOME— папка в которую распаковывался установщик. Например,/home/deployer: -
Перейдите в веб-интерфейс установщика.
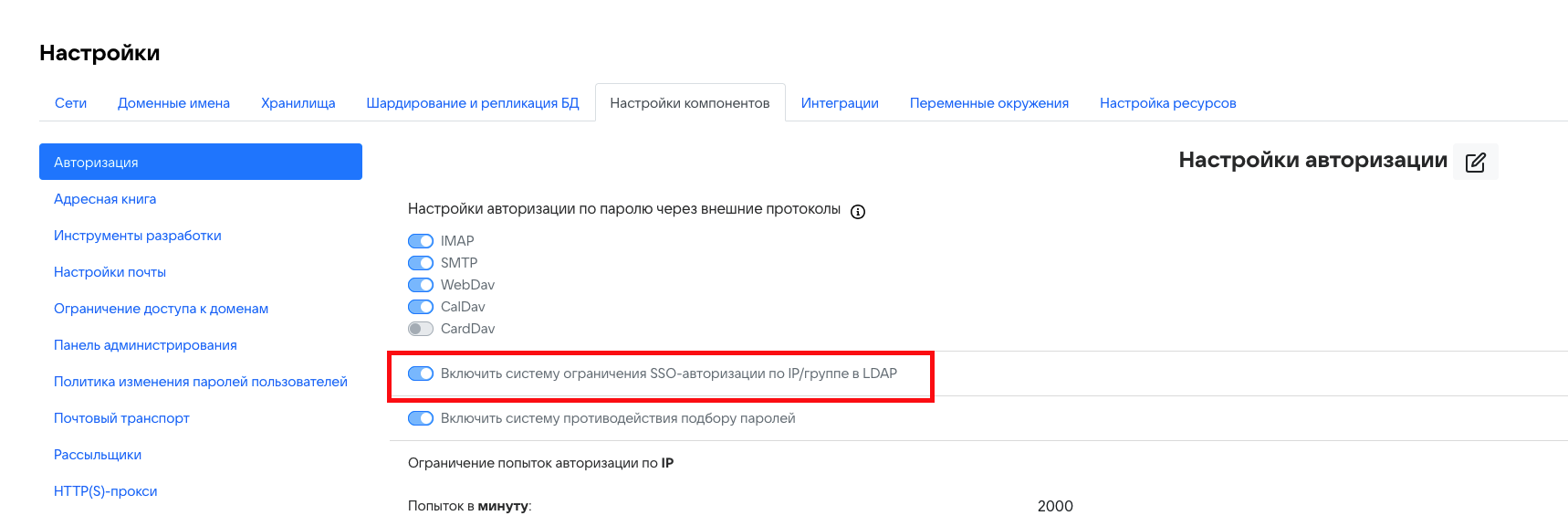
- Перейдите в раздел Настройки -> Настройки компонентов -> Авторизация.
- Нажмите кнопку редактировать
 .
. -
Включите опцию Включить систему ограничения SSO-авторизации по IP/группе в LDAP.
-
Нажмите Сохранить.
Перестала работать синхронизация с Exchange после обновления до версии 1.24
-
На машине с установщиком откройте для редактирования файл
$DEPLOYER_HOME/configs/rimap/zubr/picker-zubr.yaml, где$DEPLOYER_HOME— папка в которую распаковывался установщик. Например,/home/deployer: -
Добавьте сервис
- 94 # arbuzapiв раздел:Общий вид раздела после изменения:
-
В веб-интерфейсе установщика Почты перейдите на вкладку AdminPanel.
-
Для всех контейнеров вида picker* выполните шаг up_container.
Не синхронизируются письма с вложениям в Exchange после обновления до версии 1.24
-
На машине с установщиком откройте для редактирования файл
$DEPLOYER_HOME/configs/rimap/envoy/envoy-rimap.yaml, где$DEPLOYER_HOME— папка в которую распаковывался установщик. Например,/home/deployer: -
В раздел
static_resourcesдобавьте следующие разделы: -
Откройте для редактирования файл
$DEPLOYER_HOME/configs/rimap/zubr/zubr.yaml: -
Обновите разделы
servicesиvariables:constructor: services: - 77 # FILEDB_NONCORP - 79 # PAIRDB ... variables: filedb_noncorp_server: {{- range $k, $v := (index . "tarantool15::mfiledb").clusters }} - 127.0.77.{{$k}}:3301,127.0.77.{{$k}}:3401 {{- end }} pairdb_noncorp_server: {{- range $k, $v := (index . "tarantool15::mpairdb").clusters }} - 127.0.79.{{$k}}:3301,127.0.79.{{$k}}:3401 {{- end }} -
Выполните команду:
-
В веб-интерфейсе установщика Почты перейдите на вкладку AdminPanel.
-
По очереди выполните шаг up_container для всех контейнеров rimap*.
Некорректная конфигурация кластера БД после обновления до версии 1.24
Проблема может возникать для различных контейнеров с БД, рассмотри проблему на примере контейнера cinemadb*.
Если до обновления на версию 1.24 вы по каким-то причинам удаляли контейнеры cinemadb*, то после обновления возникают проблемы с нумерацией контейнеров, репликацией кластера и запуском сервисов.
Пример 1
До обновления вы по каким-то причинам удаляли контейнеры cinemadb2 и cinemadb3. И у вас остались контейнеры cinemadb1 и cinemadb4.
Решение
- Удалите контейнер cinemadb4.
-
Переименуйте Volume в cinemadb2 с помощью команды:
-
В веб-интерфейсе установщика создайте новый контейнер cinemadb2.
Пример 2
После обновления у вас следующая нумерация контейнеров: cinemadb1, cinemadb11, cinemadb23.
Решение
- Предварительно запишите или запомните как собираетесь переименовать контейнеры cinemadb11 и cinemadb23. Например: cinemadb11 -> cinemadb2 и cinemadb23 -> cinemadb3.
- Остановите и удалите контейнеры cinemadb11 и cinemadb23. Если удалить только контейнер cinemadb23, то новый контейнер создастся с названием cinemadb12.
- В веб-интерфейсе установщика создайте новые контейнеры cinemadb2 и cinemadb3.
-
Переименуйте Volume в cinemadb2 и cinemadb3 с помощью команд:
-
Выполните шаг up_container для контейнеров cinemadb2 и cinemadb3.
Расширенные транспортные правила и DLP-системы
Система расширенных транспортных правил при интеграции с внешними DLP системами может привести к дублированию исходящего почтового трафика и другим непредвиденным эффектам.
Как очистить память на диске при больших .wal файлах
При работе кластерной инсталляции .wal файлы могут занимать много места на диске. Чтобы очистить место, на примере контейнера exchange-importer-pg:
-
Проверьте, что реплика имеет большой лаг в мастере PostgreSQL:
-
Проверьте статус реплики:
-
Удалите проблемный слот:
-
Проверьте, что слот удалён:
-
Остановите проблемную реплику, для которой удалили слот:
-
Удалите файлы
dataдля этой реплики: -
Запустите реплику:
-
Передайте данные из мастера:
При запуске установщика выдалась ошибка no such file or directory
Это не ошибка, а предупреждение о том, что файлов нет, так как их действительно пока еще нет (не сформировались). Не обращайте внимание, это нормально.
После запуска установщика в веб-браузере отображается «Не удается получить доступ к сайту»?
Убедитесь, что firewall отключен.
Не проходит первая авторизация в панели администратора после установки Почты
При попытке залогинится в панель администратора под пользователем admin@admin.qdit после установки Почты возникает сообщение "Неверный пароль, попробуйте еще раз"
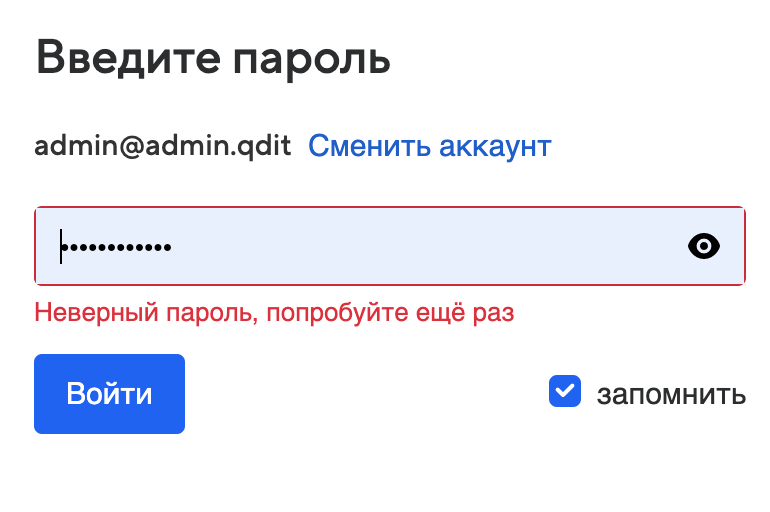
-
Перепроверить, что пароль скопирован верно.
Пароль находится в файле bizOwner.pass, файл расположен в директории с установщиком Почты onpremise-deployer_linux. Например, если установка происходила под пользователем deployer, проверить пароль можно, используя команду:
-
В веб-интерфейсе установщика перейти на вкладку AdminPanel
-
Найти в списке контейнеров fmail1 и нажать на значок шестеренки справа от названия контейнера

-
Запустить выполнение шага get_biz_owner
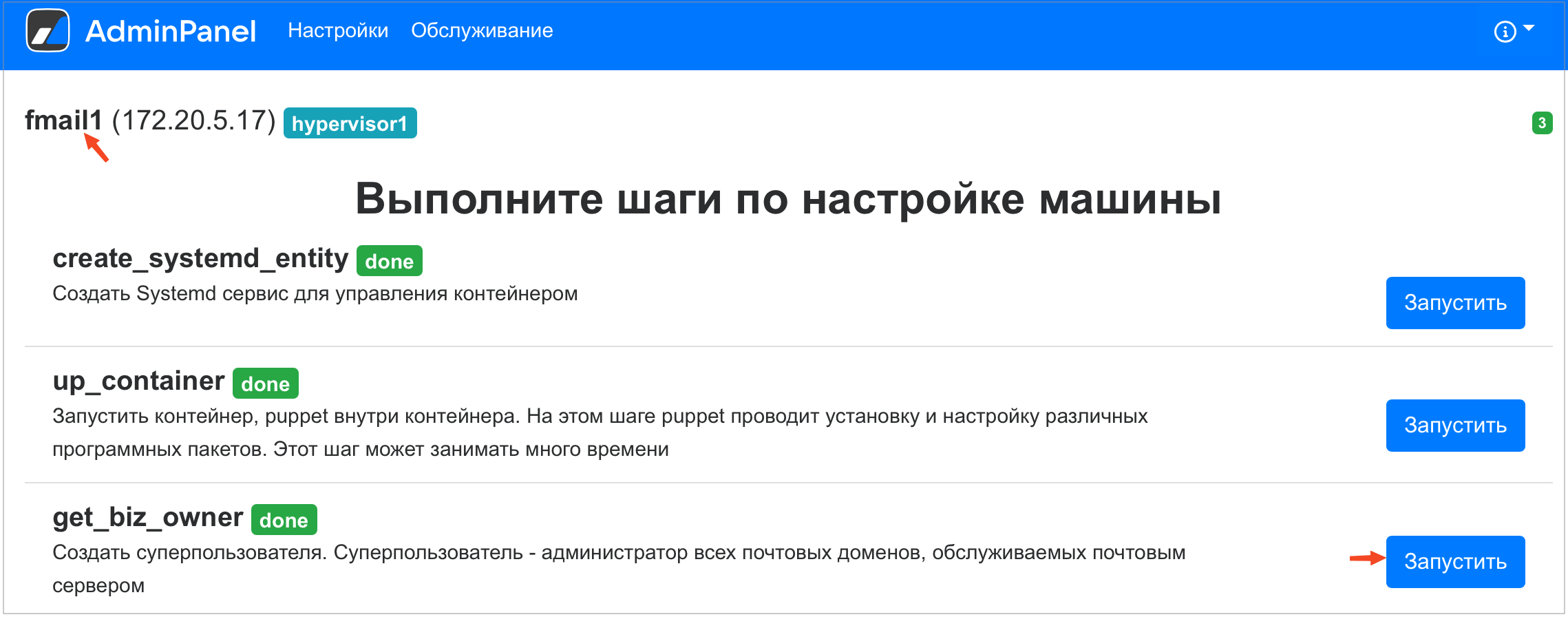
-
Поcле того как шаг get_biz_owner будет выполнен, скопировать новый пароль из файла bizOwner.pass.
Не работает вход от имени пользователя у администратора
У администратора есть возможность выполнить вход в аккаунт пользователя от его имени. Это действие не требует знания пароля, оно выполняется анонимно.
Как правило, доступ к аккаунту пользователя необходим для выполнения каких-либо операций, связанных с поддержкой. Например, если пользователь случайно очистил содержимое корзины, и нужно восстановить удаленные письма.
Чтобы получить доступ к конкретному ящику, администратор использует опцию Войти как пользователь в профиле пользователя в административной панели. Доступ к ящику пользователя предоставляется по сгенерированной ссылке. При попытке воспользоваться этой ссылкой администратор может получить сообщение про неверный пароль.
Чтобы исправить ситуацию:
-
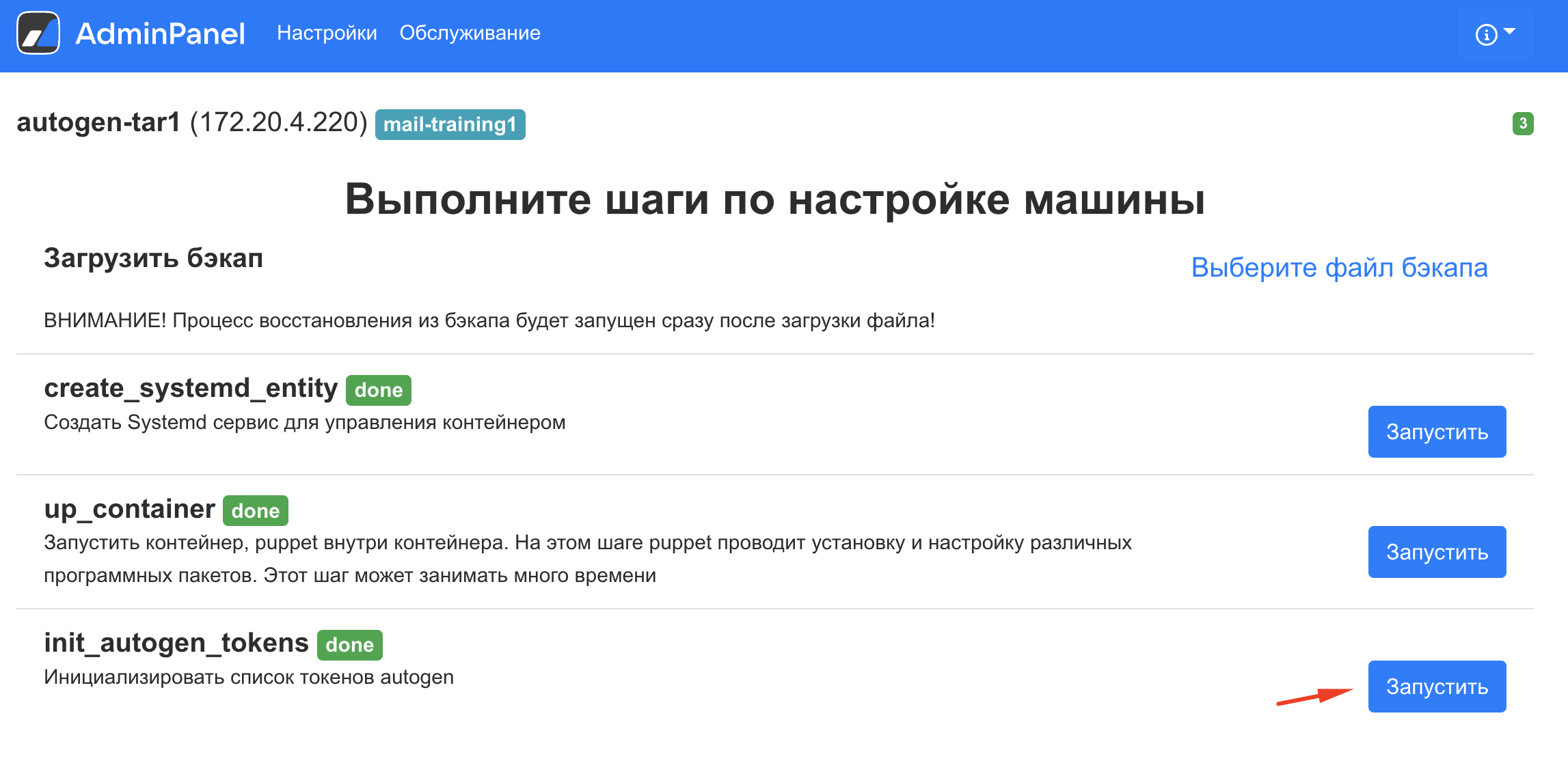
В веб-интерфейсе установщика перейдите на вкладку AdminPanel..
-
Найдите в списке контейнеров autogen-tar1 и нажмите на значок шестеренки справа от названия контейнера.

-
Запустите выполнение шага init_autogen_tokens.
Не удается зайти в Почту, на экране отображается колесо (буква С градиентом)
Последовательность действий
-
Проверьте, что сертификаты и DNS в порядке.
-
Проверьте наличие ошибок в консоли браузера (инструменты разработчика, Development Tools).
Вероятные ошибки: «ошибка загрузки login.css - 404 not found».
-
Выполните up_container для контейнера img1:
- В веб-интерфейсе установщика Почты перейдите на вкладку AdminPanel.
- Найдите в списке контейнеров img1 и нажмите на значок шестеренки справа от названия контейнера.
- Выполните шаг up_container.
Установщик не может получить доступ до гипервизора
При кластерной установке после добавления гипервизора в установщике может появиться ошибка: установщик не может получить доступ до гипервизора по ssh. Это может произойти из-за того, что автоматически выбранная сетевая маска не покрывает все узлы или соединение между машинами работает по конкретному сетевому интерфейсу.
Чтобы исправить проблему:
- В веб-интерфейсе установщика перейдите на вкладку AdminPanel.
- Найдите проблемный гипервизор и нажмите на значок шестеренки справа от названия.
-
На странице гипервизора еще раз нажмите на значок шестеренки.
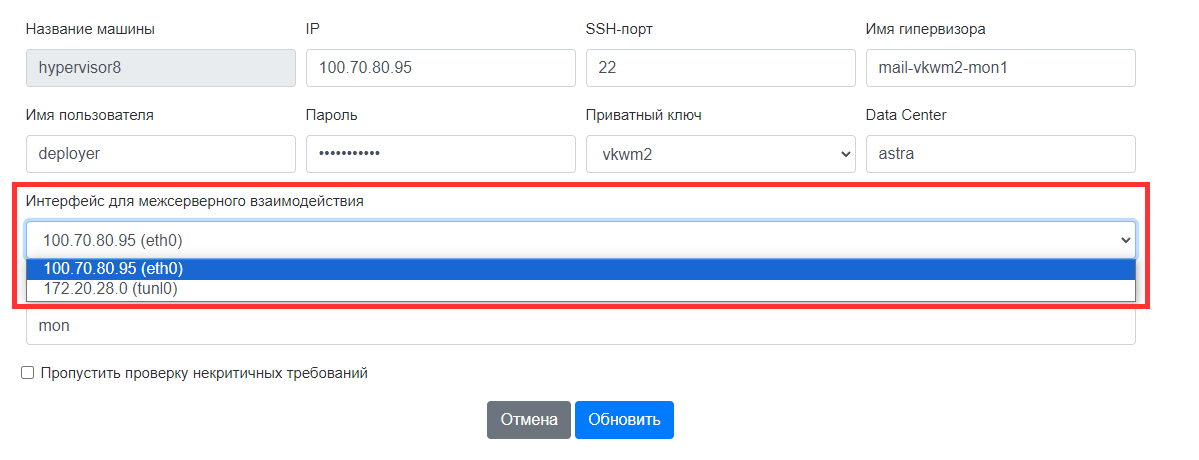
-
В поле Интерфейс для межсерверного взаимодействия выберите сетевую маску, по которой установщик сможет получить доступ по SSH к гипервизору.
-
Нажмите на кнопку Обновить.
Установка зависла, и нет явной ошибки в логах
-
Зафиксировать имя сервиса, на котором зависла установка (далее «целевой сервис»)
Найти такой сервис можно, например, в веб-интерфейсе установщика, посмотрев, установка какого сервиса находится в статусе in progress.
Также определить, на каком шаге зависла установка, можно по логам установщика. Для просмотра логов используйте следующую команду:
-
Проверить, какие сервисы еще не запустились и могут препятствовать установке целевого сервиса:
-
Проверить, какие сервисы необходимы для установки целевого сервиса. Убедиться, что незапущенные сервисы с предыдущего шага препятствуют установке:
-
Устранить причину сбоя незапущенного сервиса.
Ниже приведен пример для случая, когда зависла установка сервиса pub1:
sudo systemctl | grep onprem | grep -v running
onpremise-container-mailapi1.service loaded activating auto-restart Mail.Ru onpremise mailapi1 service
# видим, что не запустился сервис mailapi1
sudo cat /etc/systemd/system/onpremise-container-pub1.service | grep mailapi
# проверяем, что для продолжения установки pub1 должна завершить установка mailapi1
Wants=onpremise-container-mailapi1.service
After=onpremise-container-mailapi1.service
Если деплоер зависает на этапе запуска data-compose файла, то может помочь принудительное удаление data-container'ов на виртуальной машине:
Не завершается установка обновлений
Процесс установки обновления доходит до определенного этапа, после чего останавливается. Перезапуск автоматической установки, отдельный запуск шага, отмеченного красным цветом в веб-интерфейсе установщика, не дают результата.
Один из самых распространенных сценариев — проблемы на шаге генерации контейнеров. В 99% случаев не запускаются какие-то из уже установленных контейнеров. Соответственно, следует начать с их починки и запуска.
Для просмотра логов установщика используется команда:
Что исследовать?
-
Получить список всех не запущенных контейнеров:
-
Найти контейнеры со статусом auto-restrating.
У этих контейнеров, как правило, более высокий приоритет на запуск, поэтому они тормозят запуск всех остальных контейнеров.
-
Посмотреть логи конкретного контейнера
Один из вариантов решения — удалить контейнер, чтобы systemd его пересоздал.
Error 1290: The MySQL server is running with the --read-only option
Примечание
В командах ниже используется директория /home/deployer/. Но если при установке Почты вы распаковали архив с дистрибутивом в другую директорию, корректно укажите ее в командах.
При установке обновлений в логах установщика:
deployer[377192]: [mirage1][add_profile_keys] add prfoile key <ParentEmail> fail: cant insert into 'mPOP.profile_keys':
[Error 1290: The MySQL server is running with the --read-only option so it cannot execute this statement]
В веб-интерфейсе установщика красным подсвечен контейнер mirage1.
Последовательность действия для устранения ошибки:
-
Проверить какие БД в read_only (проверяем по master)
-
Снять read_only на master
Почта не доходит до сервера
Проверить состояние и логи контейнера pub-mx.
Запущенный на машине Postfix – одна из возможных причин, почему контейнер pub-mx не стартует. Соответственно, Postfix нужно остановить и отключить.
Пользователи загружены, но адресная книга пустая
Проверить tarantool'ы в abookpdd-tar
docker exec -it abookpdd-tar1 bash
tarantool -a 3303
lua box.space[0]:len()
lua for k, v in box.space[0]:pairs() do print(v) end
Не создается документ в VK WorkDisk, и в меню «Создать» не хватает кнопок
- В интерфейсе установщика перейти на вкладку AdminPanel.
- Найти в списке контейнеров mailetcd и нажать на значок шестеренки справа от названия контейнера.
- Выполнить шаг lightning_etcd_settings.
-
Найти следующие контейнеры и выполнить для каждого из них команду up_container:
- fcloud
- beaver
- lightning1
-
Найти в списке контейнеров cld-docs и нажать на значок шестеренки справа от названия контейнера.
- Выполнить шаг upload_file_templates.
См. также Ошибка CE_BADBLOB при создании файла в облаке
Не создается или не включается сборщик почты
Проблема может воспроизводить при миграции, например при миграции с MS Exchange.
Симптомы
В логах контейнера biz-celery-worker-pdd*:
{"email":"user@vk.tech","status":400,"htmlencoded":true,"body":{"collect[0].server":
{"value":"exchange.vk.tech","error":"invalid"},"collect[0].port":{"error":"invalid","value":993},
"collect[0].ssl":{"value":true,"error":"invalid"}}})
В логах контейнера mpop*:
2024-09-06T14:54:48.902 E 12345 @ abcdef0123 >>> Connection error: server: exchange.vk.tech port: 993 ssl: 1
Решение
- Перейдите в веб-интерфейс установщика
http://server-ip-address:8888/. - Перейдите в раздел Настройки -> Интеграции -> Сборщик почты.
- Нажмите кнопку редактировать .
- Нажмите на кнопку + Добавить.
- В появившемся поле введите адрес вашего exchange. Например:
exchange.vk.tech. - Нажмите на кнопку Сохранить.
-
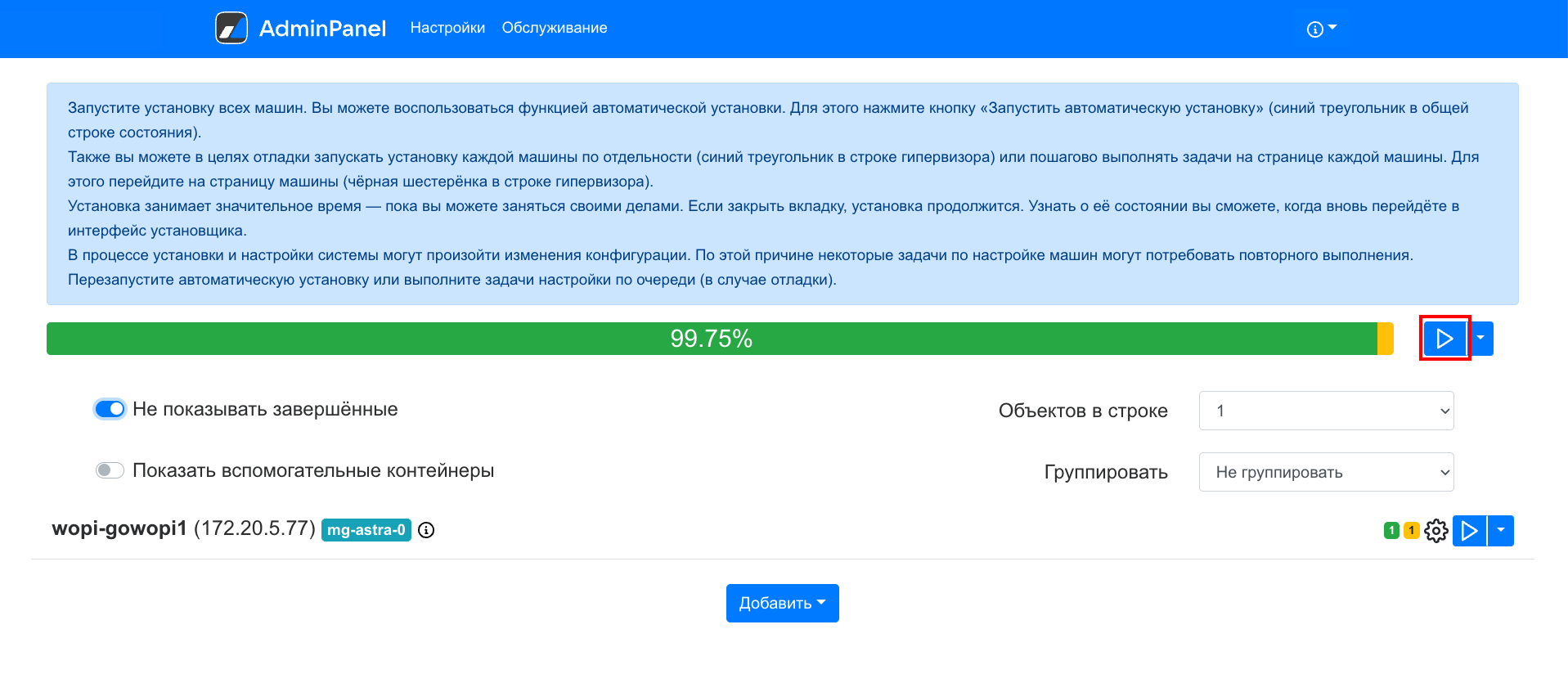
Перейдите на вкладку AdminPanel и запустите автоматическую установку.
-
Подтвердить запуск автоматической установки, нажав на кнопку Запустить во всплывающем окне.
Дождитесь окончания установки.
Ошибка refused local port forward
Симптомы
В логах установщика выводится ошибка:
2024-10-03T12:53:06.119295+03:00 m-mail sudo[26695]: deployer : TTY=pts/3 ; PWD=/home/deployer ; USER=root ; COMMAND=/bin/echo ok
2024-10-03T12:53:06.129066+03:00 m-mail sudo[26695]: pam_unix(sudo: session): session opened for user root(uid=0) by deployer(uid=1007)
2024-10-03T12:53:06.130101+03:00 m-mail sudo[26695]: pam_unix(sudo: session): session closed for user root
2024-10-03T12:53:06.700493+03:00 m-mail sshd[4840]: refused local port forward: originator 0.0.0.0 port 0, target 10.132.65.24 port 2379
Решение
Ошибка возникает в случае, если в настройках SSH на машине не разрешен TCP Forwarding. Чтобы изменить настройку TCP Forwarding, в файле /etc/ssh/sshd_config установите следующее значение:
Если ошибка была найдена во время установки Почты, то после изменения файла /etc/ssh/sshd_config перезапустите установщик, чтобы он сбросил активные ssh подключения:
ICS файлы не обрабатываются Календарем
Чтобы файлы с расширением .ics корректно обрабатывались Календарем, нужно настроить отправку уведомлений под пользователем отличным от admin@admin.qdit:
- Перейдите в панель администратора по адресу
biz.<mail_domain>. - Перейдите в раздел Почта -> Настройки.
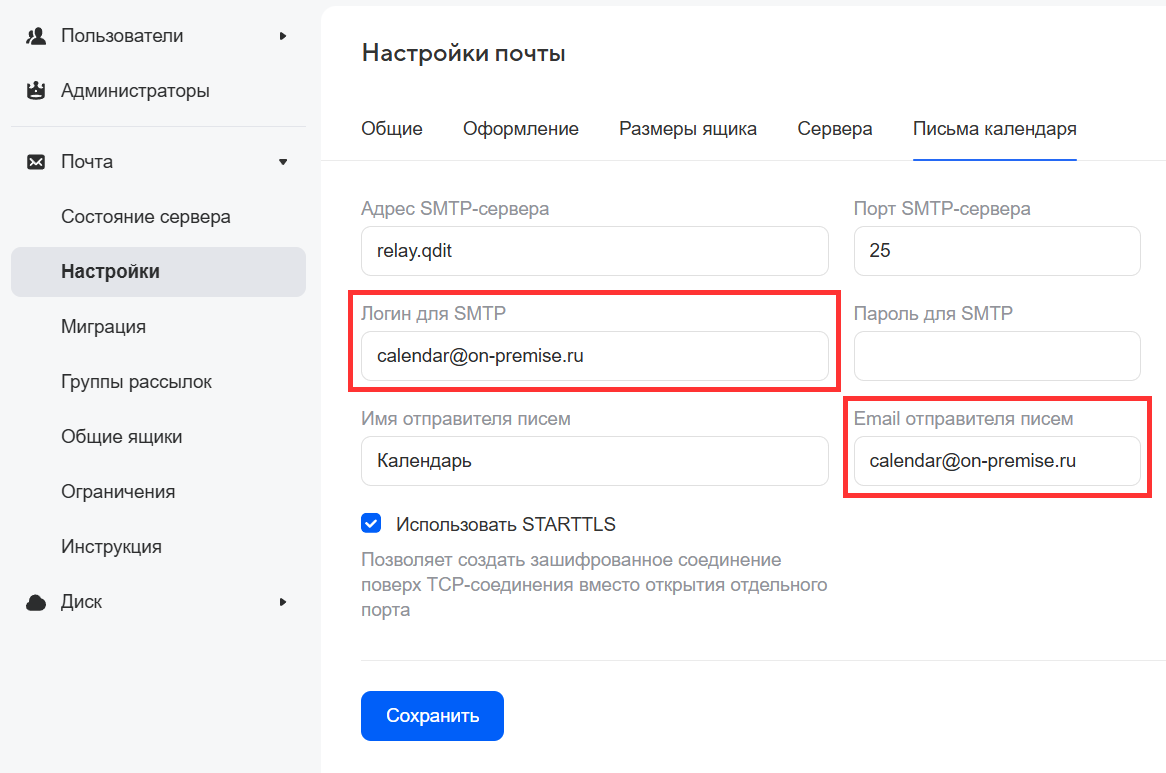
- Переключитесь на вкладку Письма календаря.
-
В поля Логин для SMTP и Email отправителя писем введите адрес пользователя, от имени которого будут отправляться письма-уведомления.
-
Нажмите кнопку Сохранить.
Ошибка в контейнере addrbook-tar1.service при установке Почты 1.20.2
Симптомы
При попытке установки VKWorkMail 1.20.2 происходит ошибка контейнера onpremise-container-addrbook-tar1.service. В логах dmesg в момент воспроизведения проблемы присутствуют ошибки:
cali0: renamed from temp6ccdc4087c0
docker-entrypoi[732625] vsyscall attempted with vsyscall=none ip:ffffffffff600400 cs:33 sp:7ffd3bb7fe68 ax:ffffffffff600400 si:7ffd3bb81daf di:0
docker-entrypoi[732625]: segfault at ffffffffff600400 ip ffffffffff600400 sp 00007ffd3bb7fe68 error 15 likely on CPU 28 (core 0, socket 56)
Code: Unable to access opcode bytes at 0xffffffffff6003d6.
Решение
-
Добавьте в файл
/etc/default/grubстроку: -
Перезагрузите операционную систему.