Единый дашборд
Назначение документа
В релизе 26.1 VK WorkSpace появилась возможность просматривать общее состояние системы и ключевые показатели системы на одном дашборде в Grafana. Также появилась возможность настраивать уведомления при сбоях или перегрузках системы по основным показателям системы.
Дашборд (dashboard) — это панель в системе мониторинга, где в одном месте собраны ключевые показатели состояния инфраструктуры и сервисов. На дашборде выводятся графики, таблицы, статусы, метрики: CPU, RAM, диски, сеть, ошибки приложений, доступность.
Алерт (уведомление, оповещение) — это автоматическое уведомление о событии или превышении заданного порога или условия. Например: «Сервис недоступен, место на диске < 10%, рост ошибок 5xx, задержки выше нормы».
Чтобы перейти в дашборд:
- Авторизуйтесь в Панели администратора VK WorkSpace.
-
Перейдите в веб-интерфейс Grafana:
biz.<domain>/grafana/.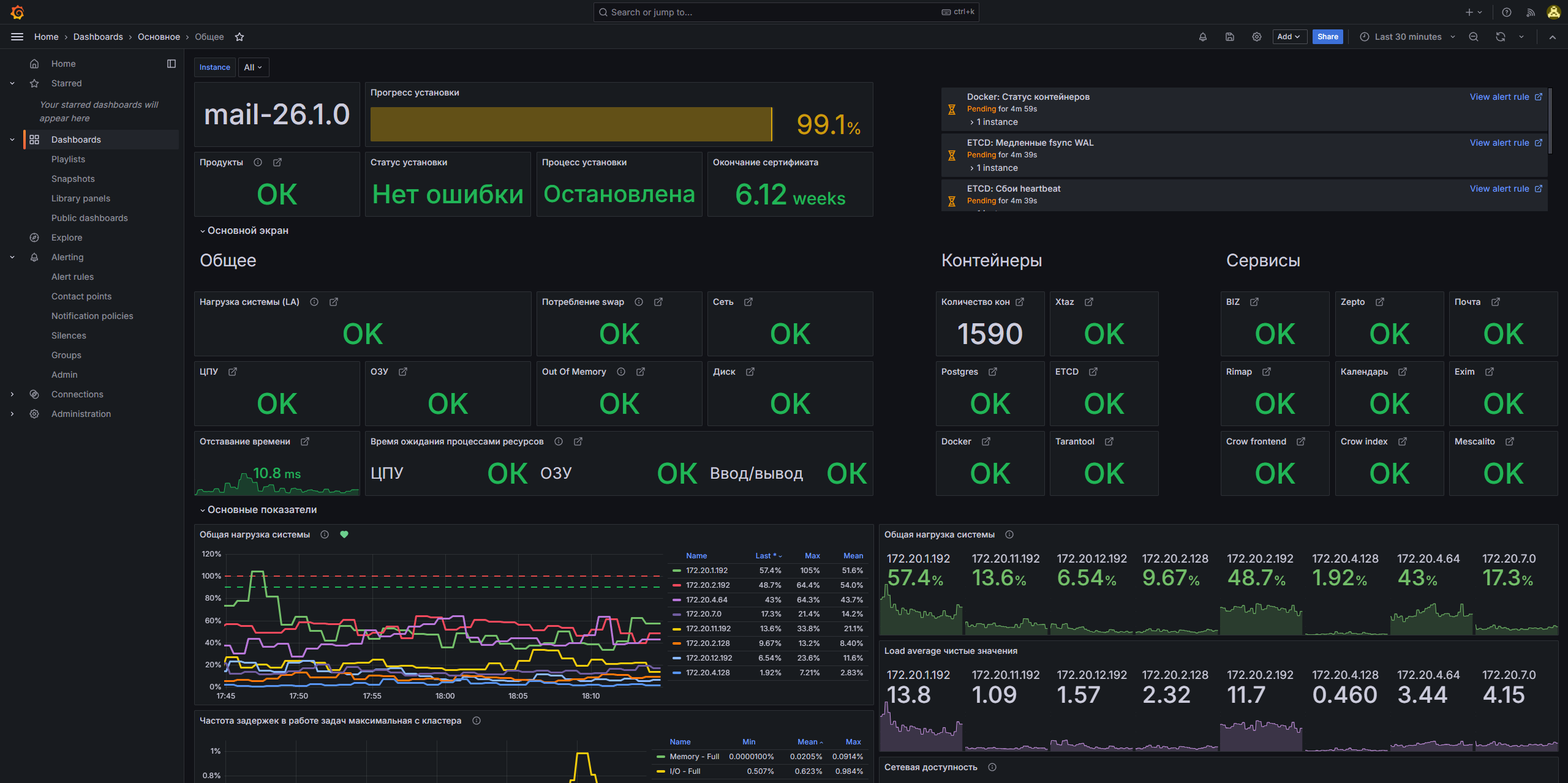
Уведомления
Чтобы настроить уведомления (алерты) при проблемах с системой, в веб-интерфейсе установщика перейдите в раздел Настройки -> Настройки компонентов -> Конфигурация Grafana.
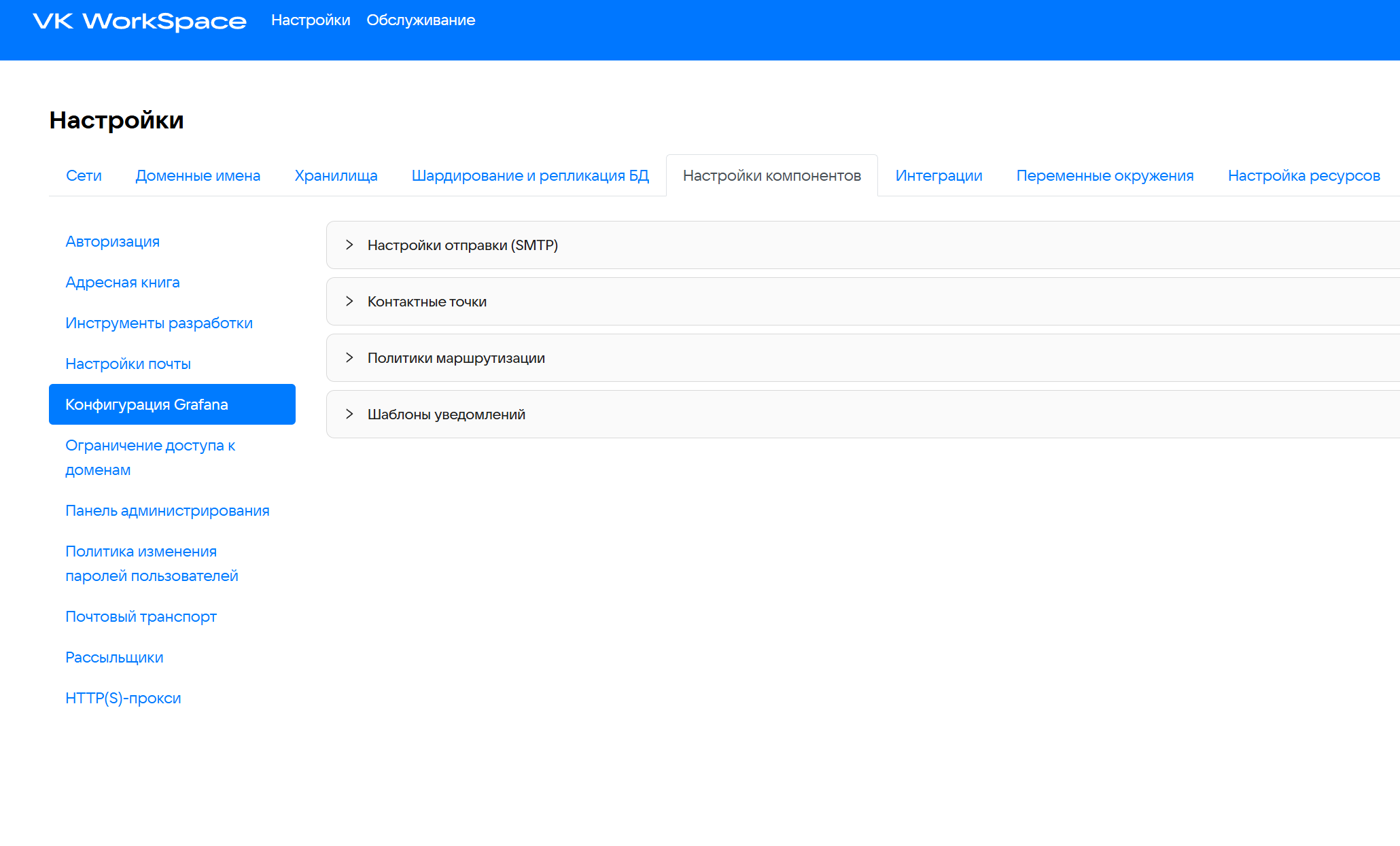
Шаг 1. Настройте отправку уведомлений
Настройки отличаются в зависимости от получателей:
- Все получатели являются пользователями VK WorkSpace.
- Есть получатели, которые не являются пользователями VK WorkSpace.
Все получатели — пользователи VK WorkSpace
- Раскройте меню Настройки отправки (SMTP).
- Нажмите Настроить.
-
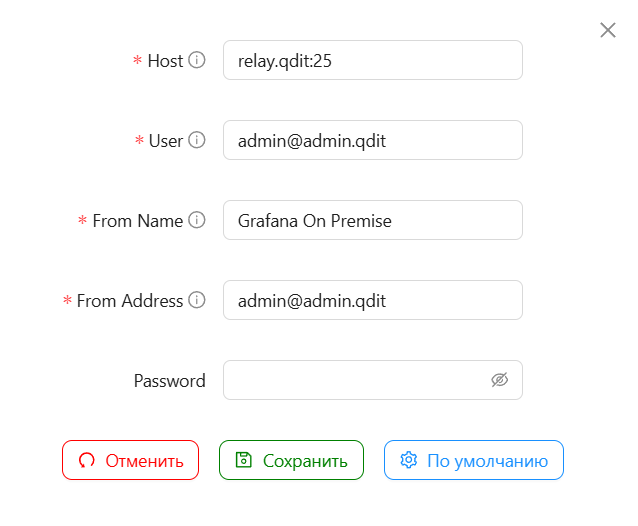
Проверьте настройки и измените их при необходимости. Можно установить параметры в соответствии со скриншотом ниже. Можете создать отдельного пользователя для отправки уведомлений.
- Host — SMTP сервер хостенейм и порт.
- User — email пользователя для SMTP аутентификации.
- From Name — имя, которое будет использоваться при отправке писем.
- From Address — email для отправки письма.
- Password — пароль.
-
Нажмите Сохранить.
- Запустите автоматическую установку на главной странице.
Есть получатели вне VK WorkSpace
Для отправки уведомлений вы также можете использовать внешний почтовый сервер. Для этого в поле Host укажите адрес внешнего почтового сервера и укажите данные от пользователя на этом сервере.
Чтобы настроить отправку уведомлений для внешних получателей:
- Предварительно в панели администратора создайте отдельного пользователя для отправки уведомлений по инструкции: Добавление одного пользователя. Например:
grafana@on-premise.ru. - В веб-интерфейсе установщика раскройте меню Настройки отправки (SMTP).
- Нажмите Настроить.
- В поле Host укажите
smtp.<ваш домен>:465. - В поле User и From Address укажите email пользователя из пункта 1.
- В поле From Name укажите имя, которое будет использоваться при отправке писем.
- Введите пароль пользователя их пункта 1 в поле Password.
- Нажмите Сохранить.
- Запустите автоматическую установку на главной странице.
-
Добавьте транспортное правило, чтобы внешние пользователи не получали лишние данные: Создание транспортного правила. Пример:
Шаг 2. Добавьте получателей уведомлений
Уведомления рассылаются двумя способами:
- По email-адресам.
- Через webhook.
Чтобы добавить получателя:
- Раскройте меню Настройки отправки (SMTP).
- Нажмите Добавить стандартные.
- При необходимости внесите изменения в стандартных получателей или добавьте новых по кнопке Создать.
-
Заполните поля в зависимости от способа рассылки:
Поле Назначение Имя Название контактной точки Email Email-адреса получателя AutoResolve Автоматическое уведомление о разрешении алерта SingleEmail Отправить сообщение сразу всем получателям Subject Специализированная тема письма. Если вы хотите, чтобы тема писем отличалась для пользователей из контактной точки. Message Специализированное тело письма. Если вы хотите, чтобы тело писем отличалась для пользователей из контактной точки. UploadImage Вкладывать изображения как вложения DisableResolveMessage Отключить отправку письма при восстановлении алерта Поле Назначение Имя Название контактной точки URL — HTTP Method Метод в API. Max Alerts Максимальное количество алертов в одном запросе. 0 - без ограничений Тип авторизации Title Шаблон заголовка сообщения Message Шаблон тела сообщения Disable Resolve Message Не отправлять сообщение при восстановлении -
Нажмите Сохранить.
Шаг 3. Настройте политики маршрутизации
В этом разделе определяются условия маршрутизации уведомлений по контактным точкам из Шага 2.
- Раскройте меню Политики маршрутизации.
- Нажмите Добавить стандартные.
-
При необходимости добавьте дочерние политики или отредактируйте стандартные.
Шаг 4. Настройте шаблоны уведомлений
- Раскройте меню Настройки отправки (SMTP).
- Нажмите Добавить стандартные.
-
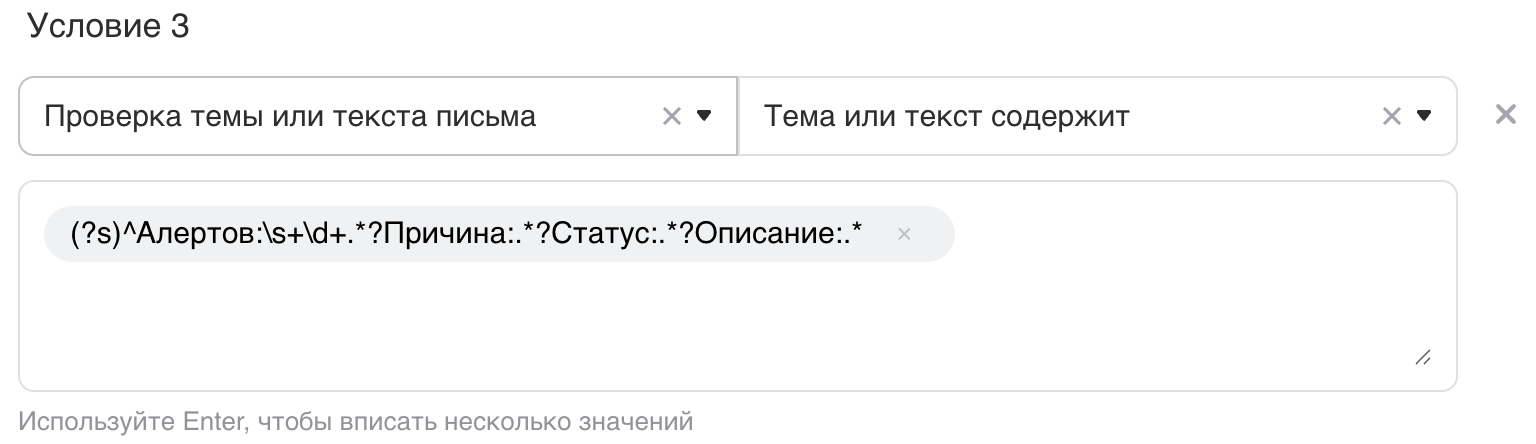
При необходимости добавьте свои шаблоны по кнопке Создать. Например:
{{ define "inside" -}} Алертов: {{ len .Alerts }} {{ range .Alerts -}} {{ template "alert.summary_and_description_inside" . -}} {{ end -}} {{ end -}} {{ define "alert.summary_and_description_inside" }} Причина: {{.Annotations.summary}} {{ if eq .Status "firing" -}} Статус: Проблема {{- else -}} Статус: Решено {{- end }} **Описание**: {{.Annotations.description}} Дашборд: {{.DashboardURL}} Панель: {{ .PanelURL }} {{ if .Annotations.details }} Подробности: {{.Annotations.details}} {{ end }} {{ end -}} -
Нажмите Сохранить.
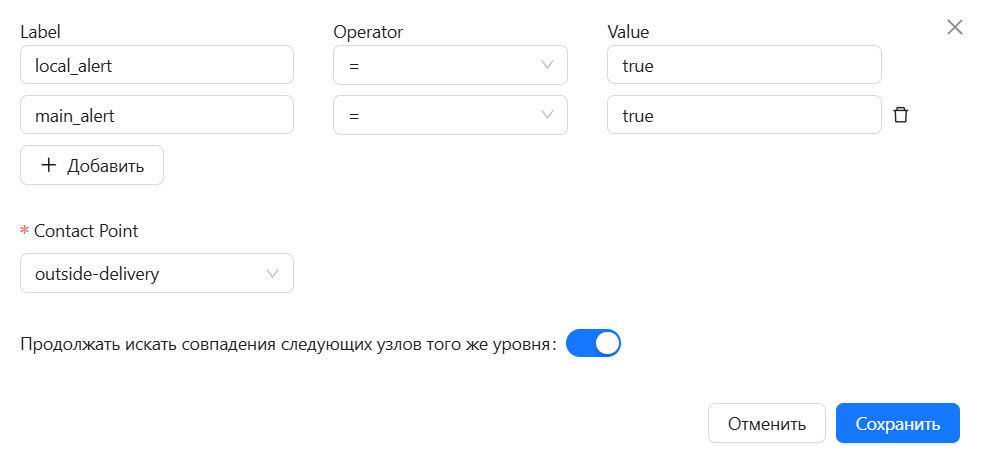
Шаг 5. Настройка переопределений алертов
Параметры переопределения применяются поверх базовых правил при настройке Grafana. Это гарантирует, что пользовательские изменения не удаляются при обновлении поставляемых шаблонов.
Для переопределения алертов:
-
Раскройте меню Переопределение алертов.
-
Выберите необходимый алерт, выполнив поиск в блоке Добавить алерт.
-
Раскройте меню Настройки переопределения выбранного алерта.
-
Укажите параметры переопределения:
- Аннотации (
annotations) — позволяет настроить текст описания уведомления (description, summary и др.). - Метки (
labels) — позволяет добавить или переопределить лейблы уведомления (severity, команда и др.). - Приостановка (
is_paused) — позволяет поставить уведомленние на паузу.
Примечание
Если при переопределении алерта требуется добавить дополнительный текст, добавьте его в annotations, а затем используйте соответствующую аннотацию в шаблонах уведомлений.
- Аннотации (
-
Нажмите Сохранить все.
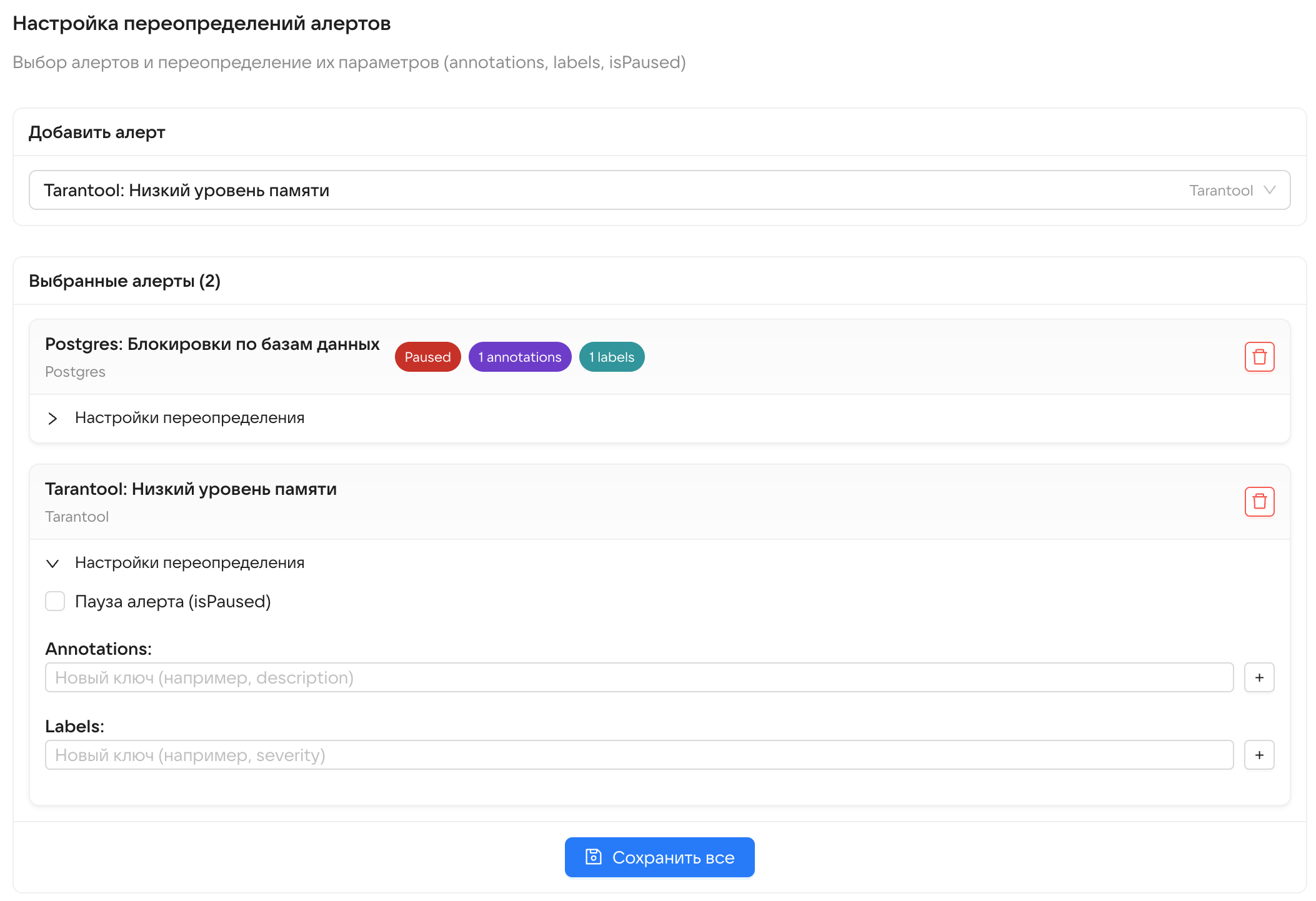
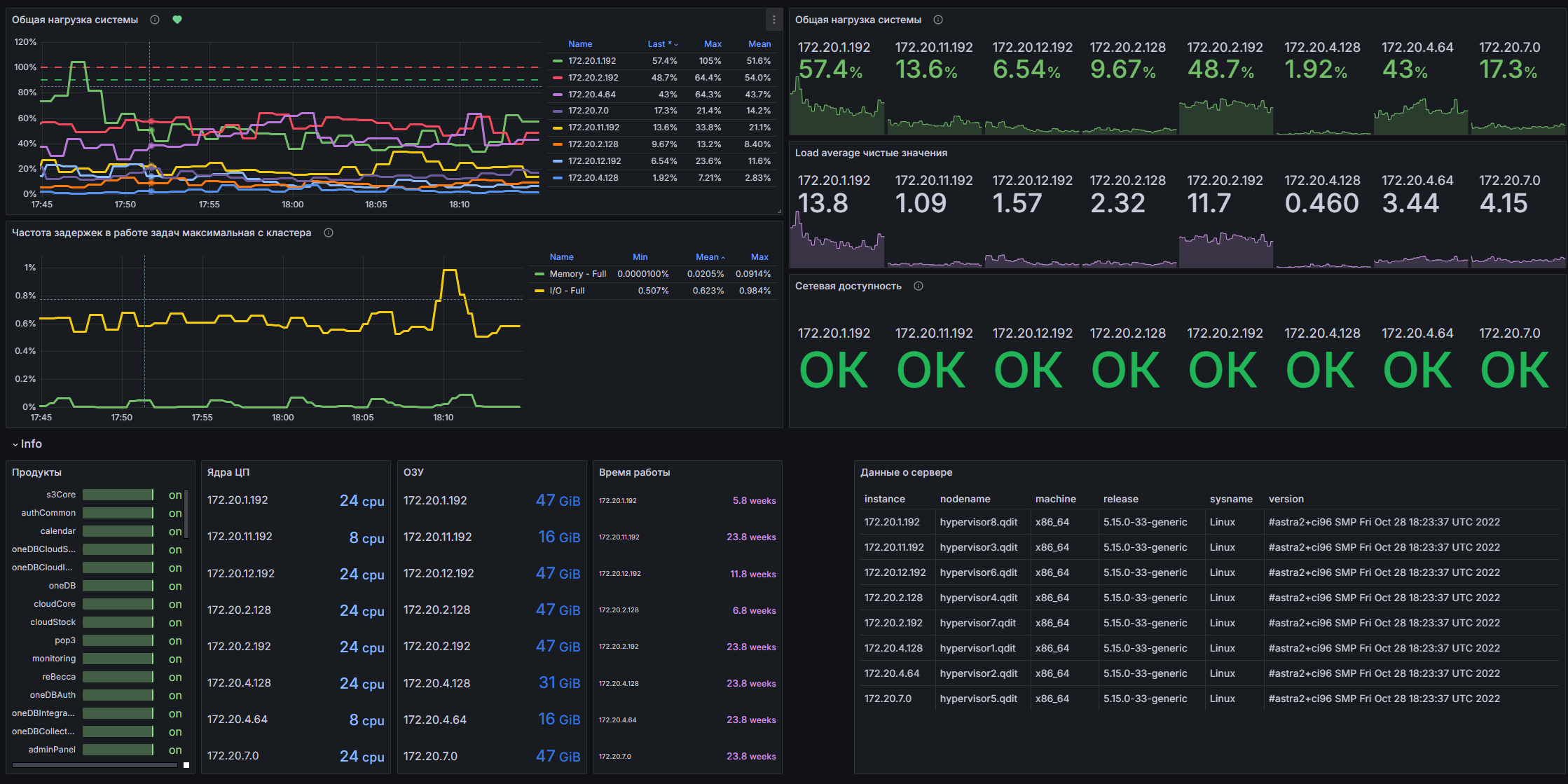
Какие данные выводятся на дашборде
Общие данные о продукте
- Версия Почты.
- Прогресс установки.
- Состояние установки: остановлена, идет или завершена.
- Оставшееся время действия сертификата.
- Включенные опции со страницы Продукты в веб-интерфейсе установщкиа.
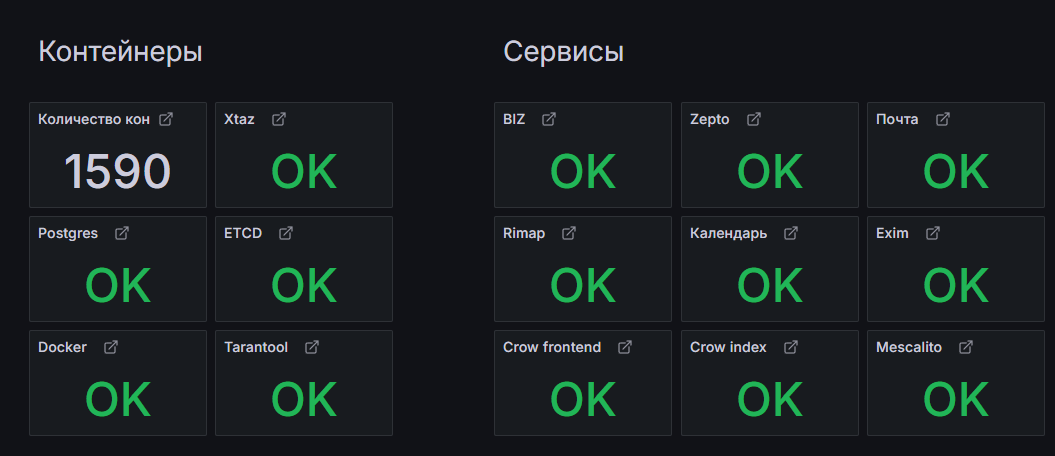
Состояние ключевых компонентов системы
Здесь отображается состояние сервисов в соответствии с перечнем правил по каждому сервису. Если наблюдаются ошибки в работе сервиса, вы сможете увидеть это на дашборде:
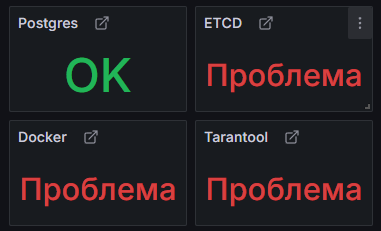
- Хранение писем: xtaz, Mescalito, Zepto.
- ETCD
- PostgreSQL
- Docker
- Tarantool
- Сборщики: rimap.
- Почтовый транспорт: exim.
- Полнотекстовый поиск: crow-frontend, crow-index.
- Панель администратора
- Календарь
- Почта
Данные о серверах и нагрузке
- Общая нагрузка системы по каждому серверу. Процентное соотношение нагрузки, выраженное в показателе load average по отношению к количеству ядер на сервере.
- Частота задержек в работе задач, связанных с процессором, памятью или вводом-выводом.
- Сетевая доступность от каждого сервера к каждому.
- Количество CPU и ОЗУ.
- Время работы каждого сервера.
- Общие данные о каждом сервере: разрядность системы, операционная система и версия, имя гипервизора, IP-адрес.
Как посмотреть подробную информацию
Чтобы посмотреть дашборды по конкретному сервису или компоненту системы кликните на иконку рядом с названием сервиса:
Правила проверки состояния сервисов
Панель администратора (BIZ)
Рассинхрон пользователей — Рассинхрон пользователей по ID между Почтой и Панелью администратора.
- Порог: count > 0
- Выражение (Graphite):
sortByName(aliasByNode(groupByNodes(stats.counters.biz-celery-worker-pdd-check*.check_users_sync_mpop.*.mid.count, 'sum', 4), 0, 1, 2, 3, 4), true, true)
sortByName(aliasByNode(groupByNodes(stats.counters.biz-celery-worker-pdd-check*.check_users_sync_mpop.*.not_found.count, 'sum', 4), 0, 1, 2, 3, 4), true, true)
sortByName(aliasByNode(groupByNodes(stats.counters.biz-celery-worker-pdd-check*.check_users_sync_mpop.*.ok.count, 'sum', 4), 0, 1, 2, 3, 4), true, true)
Процент успеха задач за день — Процент успеха celery задач за день.
- Порог: last < 95
- Выражение (PromQL):
sum(round(increase(celery_task_succeeded_total{job="biz-celery-beat",queue_name=~"(celery|pdd|pdd_check|pdd_high|pdd_subscriptions|pdd_update)"}[1d]))) / (sum(round(increase(celery_task_succeeded_total{job="biz-celery-beat",queue_name=~"(celery|pdd|pdd_check|pdd_high|pdd_subscriptions|pdd_update)"}[1d]))) + sum(round(increase(celery_task_failed_total{job="biz-celery-beat",queue_name=~"(celery|pdd|pdd_check|pdd_high|pdd_subscriptions|pdd_update)"}[1d])))) * 100
Ошибки воркеров — Сумма ошибок воркеров превысила допустимое значение за последние 5 минут.
- Порог: count > 0
- Выражение (Graphite):
Crow index
Executors busy workers farms (Vimana) — Максимальное время выполнения команды.
- Порог: max > 60000000000000
- Выражение (Graphite):
aliasByNode(highestCurrent(crowd_index.*.executor.ReaderPl.max_busy_ns, 5), 1, 3)
aliasByNode(highestCurrent(crowd_index.*.executor.WriterPl.max_busy_ns, 5), 1, 3)
aliasByNode(highestCurrent(crowd_index.*.executor.ServicePl.max_busy_ns, 5), 1, 3)
Transaction errors farms — Ошибки при коммите транзакции.
- Порог: sum > 0
- Выражение (Graphite):
timeShift(highestMax(crowd_index.*.index.*.transaction.uncommited.corruption, 1), '1m', true, false)
timeShift(highestMax(crowd_index.*.index.*.transaction.uncommited.noSpaceLeftOnDevice, 1), '1m', true, false)
timeShift(highestMax(crowd_index.*.index.*.transaction.uncommited.total, 1), '1m', true, false)
Executors unhandled exceptions — Необработанные исключения в экзекьюторах.
- Порог: sum > 0
- Выражение (Graphite):
alias(crowd_index.crow-index1.executor.FileHashVer.unhandled_exceptions.count, 'file_hash')
alias(crowd_index.crow-index1.executor.ReaderPl.unhandled_exceptions.count, 'reader')
alias(crowd_index.crow-index1.executor.WriterPl.unhandled_exceptions.count, 'writer')
alias(sumSeries(crowd_index.*.executor.*.unhandled_exceptions.count), 'unhandled_msearch')
Crow frontend
API codes — Неуспешные коды ответа сервиса.
- Порог: last > 15
- Выражение (Graphite):
alias(sumSeries(crow_frontend.msf.*.api_200_sum_1m0s), '200')
alias(sumSeries(crow_frontend.msf.*.api_400_sum_1m0s), '400')
alias(sumSeries(crow_frontend.msf.*.api_499_sum_1m0s), '499')
alias(sumSeries(crow_frontend.msf.*.api_500_sum_1m0s), '500')
alias(sumSeries(crow_frontend.msf.*.api_503_sum_1m0s), '503')
ETCD
Смена лидера — Увеличилось количество смен лидера в кластере ETCD. Это может привести к кратковременным блокировкам записи и снижению доступности кластера.
- Порог: last > 3
- Выражение (PromQL):
Квоты хранилища — Квота хранилища ETCD приближается к критическому значению (обычно >80%).
- Порог: last > 80
- Выражение (PromQL):
Наличие лидера — Кластер ETCD остался без действующего лидера. Операции записи (PUT, DELETE) недоступны. Требуется немедленное вмешательство.
- Порог: last < 1
- Выражение (PromQL):
Свободное место — Критически мало свободного места в хранилище ETCD. Риск перехода кластера в режим только для чтения.
- Порог: last < 500000000
- Выражение (PromQL):
Время коммита на диск — Высокая задержка коммита данных на диск в бэкенде ETCD. Операции записи выполняются неприемлемо медленно.
- Порог: last > 0.2
- Выражение (PromQL):
histogram_quantile(0.99, sum(rate(etcd_disk_backend_commit_duration_seconds_bucket[5m])) by (le, instance))
Сбои heartbeat — Лидер ETCD не может отправлять heartbeat фолловерам. Риск потери лидера и инициации новых выборов.
- Порог: last > 0
- Выражение (PromQL):
Медленные fsync WAL — Высокая задержка синхронизации WAL на диск (fsync). Это создает риск потери данных и замедляет репликацию.
- Порог: avg > 0.05
- Выражение (PromQL):
histogram_quantile(0.99, sum(rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m])) by (le, instance))
Сбои проверки работоспособности — Увеличилась частота сбоев внутренних проверок работоспособности ETCD. Указывает на проблемы связи внутри кластера.
- Порог: avg > 0
- Выражение (PromQL):
Ошибки Raft-предложений — Увеличилось количество неудачных Raft-предложений. Запросы на изменение состояния кластера не применяются.
- Порог: last > 0.01
- Выражение (PromQL):
Доля фрагментированных данных — Высокий процент фрагментированных (мусорных) данных в хранилище ETCD. Рекомендуется выполнить дефрагментацию.
- Порог: last > 60
- Выражение (PromQL):
(etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_use_in_bytes) / etcd_mvcc_db_total_size_in_bytes * 100
Exim
Длина очереди писем — Длина очереди почтового сервера Exim превысила допустимый порог. Письма не отправляются вовремя.
- Порог: last > 5000
- Выражение (PromQL):
Статусы deliveryd — Много ошибок deliveryd.
- Порог: last > 1000
- Выражение (Graphite):
groupByNode(scaleToSeconds(pulse.deliveryd.*.deliveryd.request.result_breakdown_sum.ok, 60), -1, 'sum')
groupByNode(scaleToSeconds(exclude(pulse.deliveryd.*.deliveryd.request.result_breakdown_sum.*, 'ok'), 60), -1, 'sum')
Скорость отправки сообщений — Долгая отправка писем.
- Порог: last > 900
- Выражение (Graphite):
Ошибки удаленной отправки — Ошибки удаленной отправки.
- Порог: last > 100
- Выражение (Graphite):
Ошибки локальной отправки — Ошибки локальной отправки.
- Порог: last > 100
- Выражение (Graphite):
Xtaz
Лаг очереди (почта) — Зафиксированы ошибки в процессе Mescalito. Отставание тачинга более 7 дней.
- Порог: last > 604800
- Выражение (Graphite):
Лаги компакта (почта) — Зафиксированы ошибки в процессе Mescalito. Не успевает очищаться компакт.
- Порог: last > 86400
- Выражение (Graphite):
Приоритетные компакты (почта)
- Порог: avg > 0
- Выражение (Graphite):
Ошибки очистки памяти main (почта) — Зафиксированы ошибки в процессе Mescalito. Не успевает очищаться память в main, вероятно что-то сломалось, либо компакты не справляются.
Выражение (Graphite):
Ошибки очистки памяти opt (почта) — Зафиксированы ошибки в процессе Mescalito. Не успевает очищаться память в opt, вероятно что-то сломалось, либо компакты не справляются.
Выражение (Graphite):
Mescalito
Ошибки получения оптов (почта) — Зафиксированы ошибки получения опт-записей в процессе Mescalito.
- Порог: last > 0
- Выражение (Graphite):
Критичные ошибки — Зафиксированы критические ошибки в master-процессе Mescalito. Качество обслуживания запросов degraded.
- Порог: last > 0
- Выражение (Graphite):
mescalito.mstats.*.multidomain.*.*.master.request_errors.count_sum.{fail,enomem,overload,readonly,oos,eio,worker_is_down,too_many_requests}
Загрузка основного треда воркеров — Один или несколько worker-процессов Mescalito перегружены.
- Порог: last > 50
- Выражение (Graphite):
Файберы в мастере — Аномально высокое или низкое количество файберов в master-процессе Mescalito.
- Порог: last > 500
- Выражение (Graphite):
Загрузка основного треда мастера — Основной поток master-процесса Mescalito перегружен.
- Порог: last > 50
- Выражение (Graphite):
Файберы в воркере — Аномальное количество файберов в worker-процессе(ах) Mescalito.
- Порог: last > 500
- Выражение (Graphite):
Время выполнения операций — Увеличилось среднее время выполнения операций select/modify в Mescalito.
- Порог: last > 500000000
- Выражение (Graphite):
movingAverage(keepLastValue(mescalito.mstats.*.multidomain.*.*.master.requests.time_avg.{select,modify}), 5)
Postgres
Эффективность shared buffers — Низкая эффективность shared buffers в БД.
- Порог: last > 10
- Выражение (PromQL):
100 - (sum by (job) (rate(pg_stat_database_blks_read[5m])) / (sum by (job) (rate(pg_stat_database_blks_hit[5m])) + sum by (job) (rate(pg_stat_database_blks_read[5m]))))
Количество мастер-нод — Нарушена топология репликации PostgreSQL: обнаружено неверное количество мастер-нод (не 1).
- Порог: last < 1
- Выражение (PromQL):
Лаг репликации — Критическое отставание реплики(ок) PostgreSQL от мастера.
- Порог: last > 5
- Выражение (PromQL):
Утилизация подключений — Утилизация подключений к PostgreSQL приближается к лимиту. Новые подключения могут быть отклонены.
- Порог: avg > 80
- Выражение (PromQL):
Блокировки по базам данных — Обнаружено большое количество блокировок в базе данных PostgreSQL. Возможны взаимоблокировки транзакций.
- Порог: last > 1
- Выражение (PromQL):
Tarantool
Утилизация памяти арены — Нода кластера имеет мало памяти в low arena.
- Порог: last > 90 (оба)
- Выражение (PromQL):
Низкий уровень памяти — Низкий уровень памяти (кортежей), оставшейся для экземпляра.
- Порог: last > 90 (оба)
- Выражение (PromQL):
Режим только для чтения — Мастер-инстанс(ы) Tarantool перешли в режим только для чтения. Запись в базу данных невозможна.
- Порог: within_range 1
- Выражение (PromQL):
Статус репликации — Нарушена репликация одного или нескольких инстансов Tarantool. Риск потери данных и рассинхронизации.
- Порог: last < 1
- Выражение (PromQL):
tnt_replication_status{stream="downstream", alias!~""} and on(alias) tnt_read_only{alias!~""} == 0
tnt_replication_status{stream="upstream", alias!~""} and on(alias) tnt_read_only{alias!~""} == 1
Лаг репликации — Критическое отставание реплики Tarantool от мастера. Данные на реплике сильно устарели.
- Порог: last > 300
- Выражение (PromQL):
Запросы в очереди — Большая очередь необработанных запросов к Tarantool. База данных становится узким горлышком.
- Порог: last > 500
- Выражение (PromQL):
Время цикла обработки событий — Основной поток Tarantool (event loop) перегружен и медленно обрабатывает события.
- Порог: last > 2
- Выражение (PromQL):
Zepto
Проблемы с бакетами — Недоступные для записи/чтения (broken). Часть данных может быть недоступна. Бакеты Zepto с двумя неработающими репликами (both_broken) — данные могут быть полностью недоступны. Пропавшие бакеты в кластере Zepto (missing). Возможна потеря данных или проблема с ребалансировкой.
- Порог: avg > 0
- Выражение (Graphite):
aliasSub(groupByNode(zepto_*.*.service.statusservice.host.*.cluster.*.port.*.broken_count, 0, 'sumSeries'), '^([^.]+).*', '\1 - broken')
aliasSub(groupByNode(zepto_*.*.service.statusservice.host.*.cluster.*.port.*.both_replicas_broken_count, 0, 'sumSeries'), '^([^.]+).*', '\1 - both_broken')
aliasSub(groupByNode(zepto_*.*.service.statusservice.host.*.cluster.*.port.*.missing_count, 0, 'sumSeries'), '^([^.]+).*', '\1 - missing')
Ошибки 5xx от прокси — Прокси Zepto возвращает ошибки 5xx для запросов к одному из кластеров.
- Порог: min > 0
- Выражение (Graphite):
aliasSub(groupByNode(zepto.*.service.zepto_proxy.host.*.port.*.client.*.cluster.*.method.*.http_reply_5xx_sum_per_1s_1m0s, 11, 'sum'), '$', '\1 500')
Установщик (деплоер)
Состав продуктов — Обнаружено изменение версии развернутого продукта. Возможно, было проведено обновление или откат.
- Порог: last > 0
- Выражение (PromQL):
Сбой автоматической установки — Автоматический процесс установки/обновления через установщик завершился с ошибкой.
- Порог: last > 0
- Выражение (PromQL):
(count(deployer_install_started == 0) > 0) * (count(deployer_task_status{type="fail"}> 0) > 0) * 1 or 0
Срок действия сертификата — Срок действия SSL/TLS сертификата скоро истечет (менее 30 дней). Требуется обновление.
- Порог: last < 86400
- Выражение (PromQL):
Диск
I/O Utilization — Высокая утилизация диска.
- Порог: last > 0.9
- Выражение (PromQL):
irate(node_disk_io_time_seconds_total{job="node-exporter",device=~"[a-z]+|nvme[0-9]+n[0-9]+|mmcblk[0-9]+"} [$__rate_interval])
Заполнение дискового пространства — Критически мало свободного места на одном из дисков. Это может привести к падению сервисов и невозможности записи логов.
- Порог: last > 90
- Выражение (PromQL):
(100 * (1 - (node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{fstype!~"tmpfs|overlay"})))
Docker
Статус контейнеров — Обнаружены остановившиеся (Exited) Docker-контейнеры.
- Порог: last > 0
- Выражение (PromQL):
Утилизация памяти контейнерами — Общее потребление памяти контейнерами на узле превышает критический порог. Риск OOM Killer.
- Порог: last > 85
- Выражение (PromQL):
100 * sum(container_memory_usage_bytes{image!=""}) by (instance) / sum(node_memory_MemTotal_bytes) by (instance)
Утилизация CPU контейнерами — Общая загрузка CPU контейнерами на узле достигла критического уровня.
- Порог: last > 90
- Выражение (PromQL):
100 * sum(rate(container_cpu_usage_seconds_total{image!=""}[$__range])) by (instance) / count(node_cpu_seconds_total{mode="system"}) by (instance)
Календарь
Список событий (ошибки) — Прогнозируемое кол-во [API] Список событий (ошибки) не соответствует текущему.
- Порог: sum > 20; max > 100
- Выражение (PromQL):
sum by (query) (increase(calendarapi_gql_middleware_request_duration_seconds_count{instance=~"calendarapi.*", query="query_events", status=~"internal.*"}[15s]))
Реакция на событие (ошибки) — Прогнозируемое кол-во [API] Реакция на событие (ошибки) не соответствует текущему.
- Порог: max > 20
- Выражение (PromQL):
sum by (query) (increase(calendarapi_gql_middleware_request_duration_seconds_count{instance=~"calendarapi.*", query="mutation_react_event", status=~"internal.*"}[15s]))
Обновление события (ошибки) — Прогнозируемое кол-во [API] Обновление события (ошибки) не соответствует текущему.
- Порог: sum > 8; max > 20
- Выражение (PromQL):
sum by (query) (increase(calendarapi_gql_middleware_request_duration_seconds_count{instance=~"calendarapi.*", query="mutation_update_event", status=~"internal.*"}[15s]))
Создание события (ошибки) — Прогнозируемое кол-во [API] Создание события (ошибки) не соответствует текущему.
- Порог: max > 10; sum > 8
- Выражение (PromQL):
sum by (query) (increase(calendarapi_gql_middleware_request_duration_seconds_count{instance=~"calendarapi.*", query="mutation_create_event", status=~"internal.*"}[15s]))
ICS События (ошибки)
- Порог: avg > 300
- Выражение (Vimana/Graphite):
alias(movingMedian(sumSeries(mail.mailapi_ics_processor_k8s.host.*.tntqueue.task.task_fail_sum_1m0s), '10min'), 'fails')
alias(transformNull(divideSeries(sumSeries(mail.mailapi_ics_processor_k8s.host.*.tntqueue.task.task_fail_known_sum_1m0s), #A), 0), 'known_fail')
alias(transformNull(divideSeries(sumSeries(mail.mailapi_ics_processor_k8s.host.*.tntqueue.task.task_fail_unchanged_sum_1m0s), #A), 0), 'unchanged_fail')
alias(transformNull(divideSeries(sumSeries(mail.mailapi_ics_processor_k8s.host.*.tntqueue.task.task_delete_sum_1m0s), #A), 0), 'delete')
ОЗУ
Утилизация SWAP — Утилизация SWAP.
- Порог: last > 0
- Выражение (PromQL):
Активация OOM Killer — OOM Killer был активирован и завершил один или несколько процессов. Серьезная нехватка памяти на узле.
- Порог: last > 0
- Выражение (PromQL):
Утилизация памяти — Высокий уровень использования памяти на узле. Мало доступной памяти для новых процессов.
- Порог: last > 90
- Выражение (PromQL):
Общее
Нагрузка на систему (Load Average) — Высокая системная нагрузка (Load Average) на узле. Узел перегружен и не справляется с очередью задач.
- Порог: last > 100
- Выражение (PromQL):
(node_load1 / on(instance) count(count(node_cpu_seconds_total{mode="idle"}) by (cpu, instance)) by (instance)) * 100
Почта
Mailapi Status (500) > 3000 count — Mailapi Status (500) > 3000 count
- Порог: last > 3000
- Выражение (Graphite):
alias(diffSeries(sum(pulse.e._all_.*.http_codes_by_front_subtypes_sum.e.5*,pulse.k8s_mpop._all_.*.http_codes_by_front_subtypes_sum.*.5*,pulse.e._all_.*.json_codes_by_front_subtypes_sum.e.5*,pulse.k8s_mpop._all_.*.json_codes_by_front_subtypes_sum.*.5*,pulse.e._all_.*.http_codes_by_front_subtypes_sum.apif.5*,pulse.e._all_.*.json_codes_by_front_subtypes_sum.apif.5*,pulse.e._all_.goapi.access_json_status_sum.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.*.5*),sum(pulse.{e,k8s_mpop}._all_.apache.access_api_json_status_v2_sum.500.user-signup-external-unknown,pulse.e._all_.nginx.status.xray_sum.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-survey*.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-messages-services-cleanmaster*.5*)),'5xx')
[CRITICAL] Число писем, которые доставляются дольше 60 минут — [FAIL] Аномальный рост числа писем которые доставляются дольше часа.
- Порог: avg > 100
- Выражение (Graphite):
ameliservice: большее 200 ошибок к mescalito — ameliservice ошибки походов в mescalito > 200 count.
- Порог: last > 200
- Выражение (Graphite):
alias(sumSeries(ameliservice.prod.*.request_errors.count_sum.{mescalito_connect_timeout,mescalito_request_timeout,mescalito_cant_connect,mescalito_request_failed}),'mescalito fails')
ameliservice: большее 200 ошибок в mailcloud — ameliservice ошибки походов в mailcloud > 200 count.
- Порог: last > 200
- Выражение (Graphite):
alias(sumSeries(ameliservice.prod.*.request_errors.count_sum.{mailcloud_connect_timeout,mailcloud_request_timeout,mailcloud_cant_connect,mailcloud_request_failed,mailcloud_not_found}),'mailcloud fails')
ameliservice: большее 200 ошибок в zepto (скелеты писем) — ameliservice ошибки походов в zepto (скелеты писем) > 200 count.
- Порог: last > 200
- Выражение (Graphite):
alias(sumSeries(ameliservice.prod.*.request_errors.count_sum.{zepto_cant_connect,zepto_connect_timeout,zepto_chunk_timeout,zepto_request_failed,zepto_not_found,zepto_bad_metadata,zepto_bad_resp_length}),'zepto skel fails')
Mailapi Status (500) > 300 count — Mailapi Status (500) > 300 count.
- Порог: avg > 300
- Выражение (Graphite):
alias(diffSeries(sum(pulse.e._all_.*.http_codes_by_front_subtypes_sum.e.5*,pulse.k8s_mpop._all_.*.http_codes_by_front_subtypes_sum.*.5*,pulse.e._all_.*.json_codes_by_front_subtypes_sum.e.5*,pulse.k8s_mpop._all_.*.json_codes_by_front_subtypes_sum.*.5*,pulse.e._all_.*.http_codes_by_front_subtypes_sum.apif.5*,pulse.e._all_.*.json_codes_by_front_subtypes_sum.apif.5*,pulse.e._all_.goapi.access_json_status_sum.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.*.5*),sum(pulse.{e,k8s_mpop}._all_.apache.access_api_json_status_v2_sum.500.user-signup-external-unknown,pulse.e._all_.nginx.status.xray_sum.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-survey*.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-messages-services-cleanmaster*.5*)),'5xx')
Процент "не 500" Ответов < 99% — Процент "не 500" Ответов.
- Порог: avg < 99
- Выражение (Graphite):
alias(asPercent(#B, #C),'percent')
diffSeries(sum(pulse.{e,k8s_mpop}._all_.*.http_codes_by_front_subtypes_sum.*.{1,2,3,4}*,pulse.{e,k8s_mailapi}._all_.goapi.access_json_status_sum.{1,2,3,4}*),pulse.{e,k8s_mpop}._all_.apache.access_api_json_status_v2_sum.200.{threads,messages})
diffSeries(sum(pulse.{k8s_mpop,e}._all_.apache.http_codes_by_front_subtypes_sum.*.*,pulse.{k8s_mailapi,e}._all_.goapi.access_json_status_sum.*),sum(pulse.e._all_.nginx.status.xray_sum.5*,pulse.{k8s_mailapi,e}._all_.goapi.access_api_json_status_sum.v1-messages-search*.5*,pulse.e._all_.nginx.fails.mimic_sum,pulse.{e,k8s_mpop}._all_.apache.access_api_json_status_v2_sum.200.{threads,messages}))
Mailapi Status (500) > 100 count
- Порог: avg > 100
- Выражение (Graphite):
alias(diffSeries(sum(pulse.e._all_.*.http_codes_by_front_subtypes_sum.e.5*,pulse.k8s_mpop._all_.*.http_codes_by_front_subtypes_sum.*.5*,pulse.e._all_.*.json_codes_by_front_subtypes_sum.e.5*,pulse.k8s_mpop._all_.*.json_codes_by_front_subtypes_sum.*.5*,pulse.e._all_.*.http_codes_by_front_subtypes_sum.apif.5*,pulse.e._all_.*.json_codes_by_front_subtypes_sum.apif.5*,pulse.e._all_.goapi.access_json_status_sum.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.*.5*),sum(pulse.{e,k8s_mpop}._all_.apache.access_api_json_status_v2_sum.500.user-signup-external-unknown,pulse.e._all_.nginx.status.xray_sum.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-survey*.5*,pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-messages-services-cleanmaster*.5*)),'5xx')
[Написание письма] Backend - Запросы messages/message (5хх) > 100
- Порог: last > 100
- Выражение (Graphite):
aliasByMetric(pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-messages-message.{1,2,3,4}*)
aliasByMetric(pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-messages-message.5*)
aliasByMetric(timeShift(pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-messages-message.{1,2,3,4}*, "7d"))
Процент "не 500" Ответов < 98% — Процент "не 500" Ответов < 98%.
- Порог: avg < 98
- Выражение (Graphite):
alias(asPercent(#B, #C),'percent')
diffSeries(sum(pulse.{e,k8s_mpop}._all_.*.http_codes_by_front_subtypes_sum.*.{1,2,3,4}*,pulse.{e,k8s_mailapi}._all_.goapi.access_json_status_sum.{1,2,3,4}*),pulse.{e,k8s_mpop}._all_.apache.access_api_json_status_v2_sum.200.{threads,messages})
diffSeries(sum(pulse.{k8s_mpop,e}._all_.apache.http_codes_by_front_subtypes_sum.*.*,pulse.{k8s_mailapi,e}._all_.goapi.access_json_status_sum.*),sum(pulse.e._all_.nginx.status.xray_sum.5*,pulse.{k8s_mailapi,e}._all_.goapi.access_api_json_status_sum.v1-messages-search*.5*,pulse.e._all_.nginx.fails.mimic_sum,pulse.{e,k8s_mpop}._all_.apache.access_api_json_status_v2_sum.200.{threads,messages}))
Backend - Статус messages/send (400) > 10% — Backend - Статус messages/send (400).
- Порог: avg > 1
- Выражение (Graphite):
sum(aliasByMetric(pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-messages-send.4*))
sum(aliasByMetric(pulse.k8s_mailapi._all_.goapi.access_api_json_status_sum.v1-messages-send.*))
Пререквизиты
Значения флагов ядра — Значения флагов ядра.
- Порог: различные (outside_range/lt для каждого параметра)
- Выражение (PromQL):
sysctl_net_netfilter_nf_conntrack_max
sysctl_net_ipv6_conf_all_disable_ipv6
sysctl_net_netfilter_nf_conntrack_tcp_timeout_time_wait
sysctl_net_netfilter_nf_conntrack_tcp_timeout_fin_wait
sysctl_fs_inotify_max_user_watches
sysctl_net_ipv4_tcp_syncookies
sysctl_net_ipv6_conf_default_disable_ipv6
sysctl_kernel_pid_max
sysctl_net_ipv4_tcp_tw_reuse
sysctl_fs_aio_max_nr
sysctl_fs_inotify_max_user_instances
sysctl_net_ipv6_conf_lo_disable_ipv6
cpu_flag_avx2
Проверка версии докера — Версия докера.
- Порог: last > 0
- Выражение (PromQL):
Сеть
Сетевая доступность (ping) — Потеря сетевой доступности до узла через сеть Calico (CNI).
- Порог: last < 1
- Выражение (PromQL):
Размер таблицы conntrack — Таблица отслеживания сетевых соединений (conntrack) почти заполнена. Риск блокировки установления новых сетевых подключений.
- Порог: last > 75
- Выражение (PromQL):
Система
Расхождение времени между серверами — Критическое расхождение системного времени между серверами. Может нарушать работу распределенных систем и логирование.
- Порог: last > 1
- Выражение (PromQL):
max(node_time_seconds - timestamp(node_time_seconds)) - min(node_time_seconds - timestamp(node_time_seconds))
Отсутствующие серверы — Один или несколько серверов перестали отправлять метрики (возможно, упали или потеряли сеть).
- Порог: last < 0
- Выражение (PromQL):
count by (node_uname_info) (node_uname_info) offset 10m - count by (node_uname_info) (node_uname_info)
Отклонение версии ядра — Обнаружено изменение версии ядра на одном из хостов. Требуется проверка на соответствие политике.
- Порог: last > 0
- Выражение (PromQL):
ЦПУ
Утилизация CPU — Высокая общая утилизация CPU на узле.
- Порог: last > 0.85
- Выражение (PromQL):
sum(irate(node_cpu_seconds_total{mode!="idle"}[$__rate_interval])) by (instance) / count(count(node_cpu_seconds_total) by (cpu, instance)) by (instance)
Время в пользовательском режиме — Высокая загрузка CPU процессами пользовательского пространства.
- Порог: last > 70
- Выражение (PromQL):
sum(irate(node_cpu_seconds_total{mode="user"}[$__rate_interval])) by (instance) / count(count(node_cpu_seconds_total) by (cpu, instance)) by (instance)
Ожидание ввода-вывода — Высокий процент времени ожидания ввода-вывода (iowait). Дисковая подсистема является узким горлом.
- Порог: last > 10
- Выражение (PromQL):
sum(irate(node_cpu_seconds_total{mode="iowait"}[$__rate_interval])) by (instance) / count(count(node_cpu_seconds_total) by (cpu, instance)) by (instance)
Время кражи (steal) — Высокий процент времени кражи CPU (steal time). Физический хост перегружен, ваша VM недополучает ресурсы.
- Порог: last > 10
- Выражение (PromQL):
sum(irate(node_cpu_seconds_total{mode="steal"}[$__rate_interval])) by (instance) / count(count(node_cpu_seconds_total) by (cpu, instance)) by (instance)
Переключение контекста — Аномально высокое количество переключений контекста (context switches). Может указывать на contention из-за большого количества потоков/процессов.
- Порог: last > 2
- Выражение (PromQL):
(rate(node_context_switches_total[15m])/count without(mode,cpu) (node_cpu_seconds_total{mode="idle"})) / (rate(node_context_switches_total[1d])/count without(mode,cpu) (node_cpu_seconds_total{mode="idle"}))